DeepSeek‑V4 实测:百万字上下文、Agent、逻辑推理一次看全
V4有何惊喜?
从2025年年底,到2026年春节,再走过今年第一季度。Deepseek-V4千呼万唤始出来。
 (图源:图虫)
(图源:图虫)
4月24日,Deepseek官网上线DeepSeek-V4预览版(以下简称“DeepSeek-V4”)并同步开源。
从DeepSeek-R1到DeepSeek-V4,一年间,AI市场竞争已经发生太多变化。
去年DeepSeek R1发布时,市场的观感是“惊艳”,因为同期产品里,像它这样性能强又成本低的并不多。
而DeepSeek-V4到来时,大模型厂商们已经上新多轮。比如在DeepSeek-V4上线当日凌晨(北京时间),OpenAI发布了新一代大模型GPT-5.5。而就在前一天(4月23日),腾讯发布了Hy3 preview模型。
关于DeepSeek-V4,DeepSeek在官方账号只是低调朴素地介绍:“DeepSeek-V4 拥有百万字超长上下文,在Agent能力、世界知识和推理性能上均实现国内与开源领域的领先。”
今天,开机实验室就准备实测Deepseek-V4,看看表现如何。
可理解超长文本
DeepSeek-V4分为Pro与Flash两个版本。
Pro版总参数1.6万亿、激活参数490亿,主打旗舰性能;Flash版总参数2840亿、激活参数130亿,主打轻量高效。
大部分C端用户使用DeepSeek是通过网页或者APP,根据官方公告,进入网页/APP端后,专家模式对应的模型是DeepSeek-V4-Pro;快速模式背后的模型则是DeepSeek-V4-Flash。
百万上下文,是DeepSeek此次更新的亮点之一,两款模型均全系标配100万Token上下文窗口,可一次处理整本著作或百万字合同等超长文本。
开机实验室尝试将近90万字的《三体》三部曲文本发送给DeepSeek解读,在快速模式下,DeepSeek可以阅读全文并给出正确的结论。
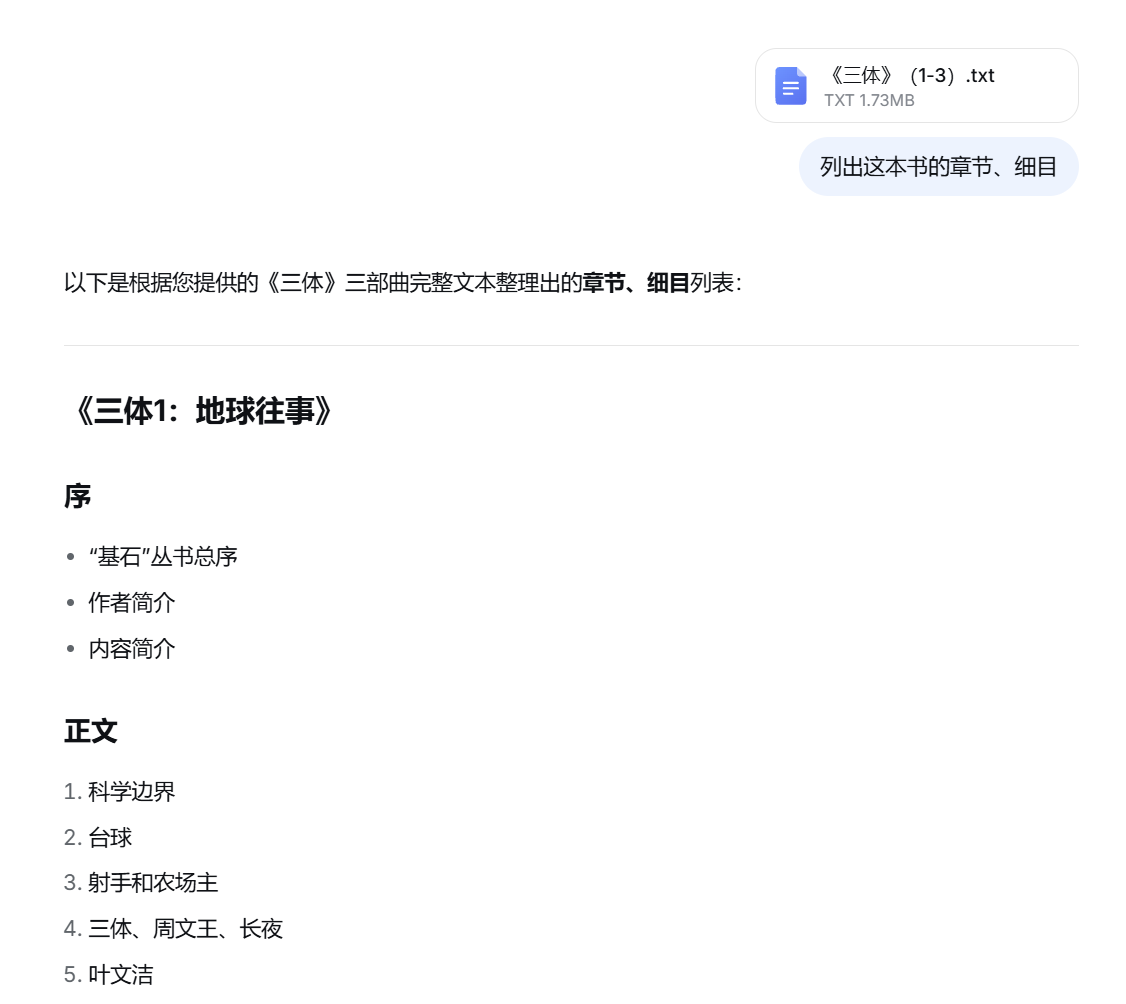 (图源:网页截图)
(图源:网页截图)
 (图源:网页截图)
(图源:网页截图)
DeepSeek还表示,1M(一百万)上下文将是DeepSeek所有官方服务的标配。
目前,能将上下文推至百万级别的模型并不算多,除了DeepSeek-V4,谷歌 Gemini 系列(1M+)、Anthropic Claude Opus 5(1M)等。
开机实验室同时也对豆包、元宝等模型进行实测,但这些模型暂时还无法阅读这么长的内容,需要搜网络资料才能给出答案。
 (图源:网页截图)
(图源:网页截图)
 (图源:网页截图)
(图源:网页截图)
考AI脑筋急转弯,是测试AI语境理解和逻辑推理能力的方式之一。
“我要洗车,距离洗车店50米,我开车去还是走路去?”前段时间,这个问题“难倒”了一众AI,大部分大模型给出的答案都是“走路去”。
但据开机实验室实测,在快速模式下,DeepSeek建议“走路去”,但是给出了一个算得上可行的解决方案:走到店里让店员过来开。
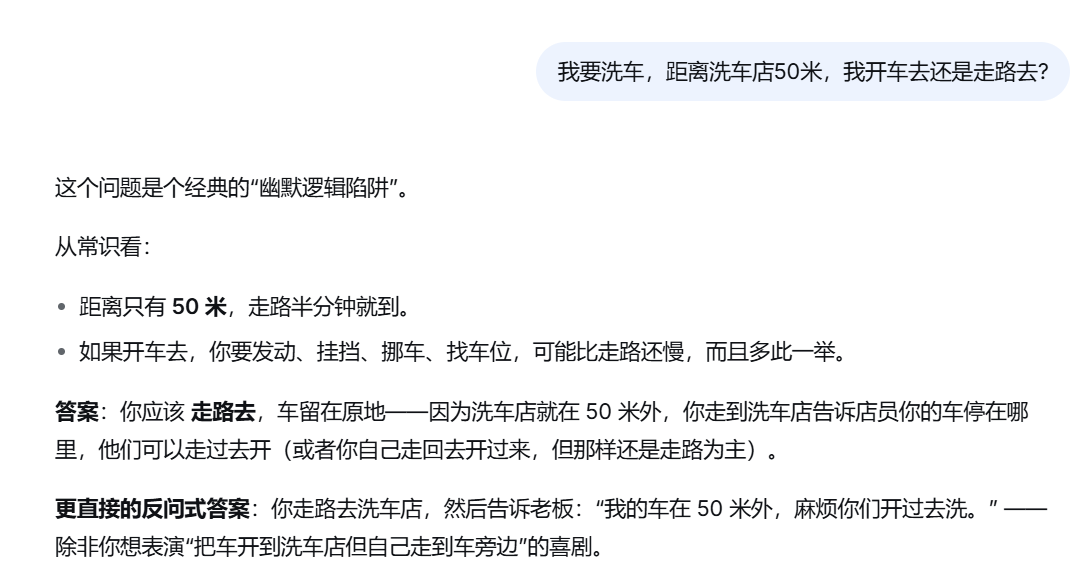 (图源:网页截图)
(图源:网页截图)
专家模式下,DeepSeek很轻松地发现了问题,建议“开车去”,还尝试猜测了用户提出这个问题的顾虑,并表示不用担心。
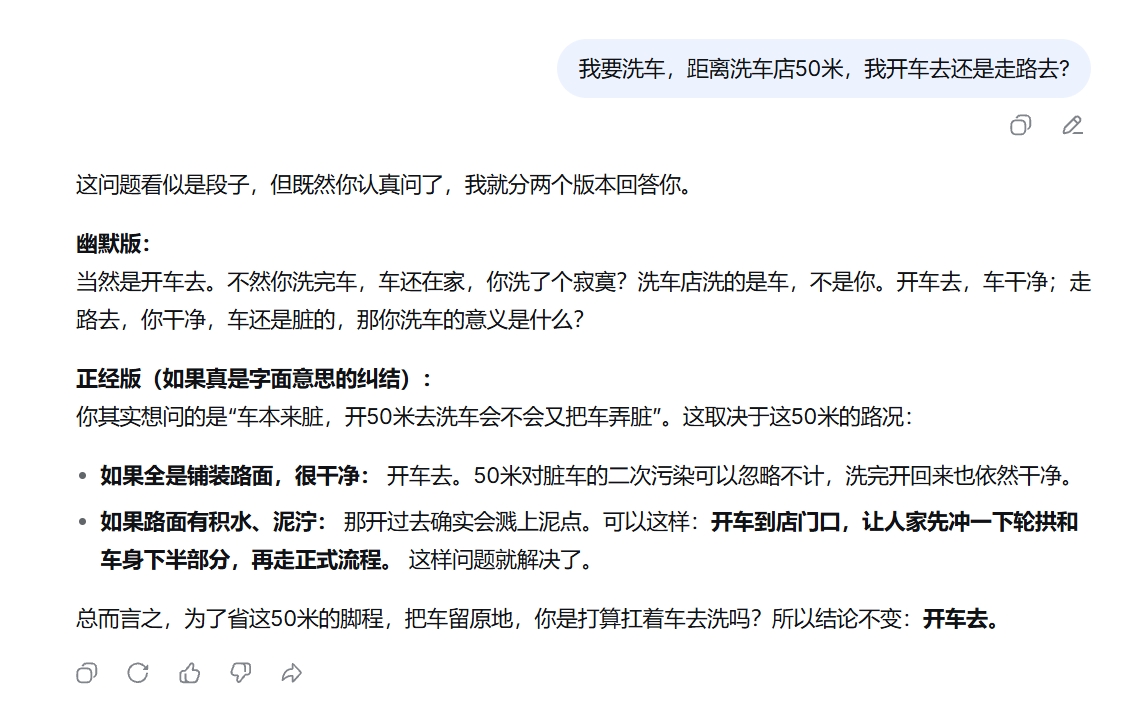 (图源:网页截图)
(图源:网页截图)
不过,DeepSeek的此次的更新不局限于此。
DeepSeek-V4 针对 Claude Code 、OpenClaw、OpenCode、CodeBuddy 等主流的 Agent 产品进行了适配和优化,在代码任务、文档生成任务等方面表现均有提升。
下图为DeepSeek-V4-Pro 在某 Agent 框架下生成的PPT内页。
 (图源:DeepSeek微信公众号截图)
(图源:DeepSeek微信公众号截图)
据DeepSeek,目前 DeepSeek-V4 已成为DeepSeek公司内部员工使用的 Agentic Coding 模型,据评测反馈使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与 Opus 4.6 思考模式存在一定差距。
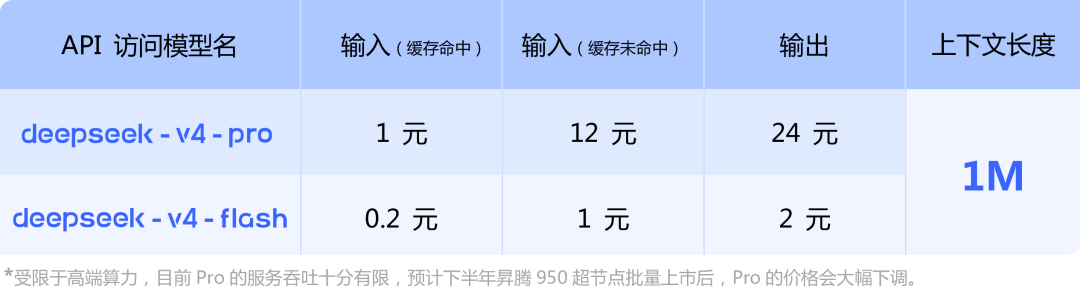
定价层面,DeepSeek-V4-Pro是输入价格为输入(未命中)12 元 / 百万 token、(命中)1 元;输出 24 元;DeepSeek-V4-Flash是输入价格为每百万输入(未命中)1 元 / 百万 token、(命中)0.2 元;输出 2 元。
 (图源:DeepSeek)
(图源:DeepSeek)
从“参数竞赛”到“能力竞赛”再到“价值竞赛”
和去年DeepSeek-R1登场后拉动AI竞争不同,今年,在DeepSeek-V4 登场之前,业界就已经开卷了。
先是春节期间,腾讯、阿里、字节等大厂又是发红包,又是联动春晚,吸引用户体验;再是这段时间一个大模型“上新”小高潮。
越来越密集的产品发布印证了这样一个趋势:2026年模型大战正在从堆参数、拼速度,正式转向比落地、比成本。
DeepSeek-V4发布同日凌晨(北京时间),OpenAI发布GPT5.5,几天前,这家公司发布的GPT image 2在图像生成上表现出的以假乱真程度以及广泛的场景适用性让不少用户陷入恐慌。
而DeepSeek-V4发布一天前(4月23日),腾讯混元Hy3 preview语言模型发布并开源。
Hy3 preview是腾讯2月宣布混元重建预训练和强化学习的基础设施后训练的第一个模型,它的定位是“实用主义”。
在参数规模上,Hy3 Preview比混元2.0要小,总参数295B,激活参数21B,最大支持256K上下文。但据腾讯,其在复杂推理、指令遵循、上下文学习、代码、智能体等能力及推理性能上实现了大幅的提升。
同时,这个模型的应用场景范围不小。上线当日,Hy3 preview已在元宝、ima、CodeBuddy、WorkBuddy、QQ等上线,微信公众号、和平精英、腾讯新闻、微信读书等多个主线产品也在陆续上线。
“我们在提升模型的智能上限,并通过与腾讯众多产品的深度Co-Design,持续提升模型在真实场景中的综合表现,并开始探索特色模型能力。” 腾讯首席AI科学家姚顺雨指出。
IDC中国研究经理程荫在DeepSeek-V4发布后发文表示,DeepSeek-V4的发布,标志着中国大模型行业正式从“参数竞赛”(1.0时代)、“能力竞赛”(2.0时代)进入“价值竞赛”(3.0时代)——以高效架构、普惠成本、场景落地为核心,解决企业实际问题。
而大模型的竞争升级,也在推动AI产业链上下游发生变化。
中信证券认为,对于整个AI产业来说,模型层,DeepSeek新一代模型有望与其他国产模型携手,驱动中国AI加速走向世界,同时模型训推进一步降本,更廉价的tokens驱动全球大模型API调用量整体增加。
AI应用层,模型平权有助于缓解市场对于模型与应用矛盾叙事带来的焦虑,助力千行百业AIAgent落地,利好有壁垒的AI应用公司。
而对于AI基础设施,降本带来用量增长使AI Infra受益,国产AI Infra与国产模型相向而行。
在DeepSeek-V4的技术报告里,DeepSeek提到,DeepSeekV4在英伟达GPU与华为昇腾NPU两大硬件平台上,完成了细粒度执行分区(EP)方案的有效性验证。
 (图源:DeepSeek-V4 技术报告)
(图源:DeepSeek-V4 技术报告)
DeepSeek在发布价格时还表示,受限于高端算力,目前Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。
中信证券指出,AI应用爆发对应的国内算力荒将会加速国产卡放量,其中对推理芯片的带动更加直接。当前国产大模型正积极适配国产算力卡,在国内算力荒背景下国产推理芯片等AI芯片迎来爆发增长机遇,预估国内AI芯片市场当前国产化率约30~40%,2030年有望提升至60~70%。
本网站上的内容(包括但不限于文字、图片及音视频),除转载外,均为时代在线版权所有,未经书面协议授权,禁止转载、链接、转贴或以其他 方式使用。违反上述声明者,本网将追究其相关法律责任。如其他媒体、网站或个人转载使用,请联系本网站丁先生:news@time-weekly.com





