开源大模型风起云涌 通义千问的关键一役
补齐开源大模型的最后一片拼图
热烈而焦灼的“百模大战”之后,大模型如何赋能千行百业成为新的创新方向。其中,在开源大模型的探索中,不少开发者或创业公司正在基于开源大模型开发属于自己的模型和应用。
例如,个人开发者陶佳利用通义千问(Qwen)开源模型搭建文档问答相关应用,探索大模型应用于电力领域的各种可能性;华东理工大学薛栋团队基于开源的通义千问基座模型开发出心理健康大模型 MindChat(漫谈)等;有鹿机器人创始人、CEO陈俊波依托自主研发的第二代具身智能技术LPLM大模型,打造软硬件高度适配与可泛化的通用智能大脑。
在这个过程中,阿里云等科技公司也通过开源基础大模型,为个人开发者、科研团队、创业公司、大中型企业提供大量的开发工具,推动大模型技术的普惠和落地应用,促进中国大模型生态繁荣。

开源大模型掀起开发潮
就职于中国能源建设集团浙江省电力设计院有限公司者陶佳,是开源大模型的一名个人开发者。
“我用很省钱的方式在玩开源模型,在家里买个服务器、扔三四块显卡上去,下载Qwen、让它在服务器上运行,再搞个FRP反向代理,从阿里云上买最便宜的30多块钱一个多月的服务就行,这样就能通过外网访问家里的服务器,在单位里也能用通义千问做实验。”陶佳说。
陶佳正在做的是用Qwen做基于私有知识库的检索问答类应用,从几十万甚至上百万字的文档中查找内容,比如,给定一个英文文档,告诉大模型需要查找的内容,请大模型根据文档目录回答,在哪个目录项下可以找到答案。
00后华东理工大学·X-D Lab(心动实验室)成员颜鑫则有着自己的科研团队,他们基于开源的通义千问基座模型开发了三款垂直领域大模型:心理健康大模型 MindChat(漫谈)、医疗健康大模型 Sunsimiao(孙思邈)、教育/考试大模型 GradChat(锦鲤)。
“MindChat是一款心理咨询工具, 像个AI心理咨询师,打工人上班被老板骂了,心里不爽;学生党写不出论文,担心影响毕业……日常生活中遇到这些事情,都可以去跟MindChat聊聊,甚至可以语音输入。”颜鑫说道。
“医疗、心理都是非常注重隐私的场景,很多客户都要求私有化部署,因此我们选择了开源模型。”颜鑫回忆称,Qwen出现之前他们试用了一些其他模型,比如ChatGLM、Baichuan、InternLM。Qwen-7B和14B推出后,他们快速进行试验,用内部数据和自己的benchmark做了测评。“在我们的场景中,通义千问是所有的开源模型里发挥最好的,是目前最优解。”
围绕开源大模型的开发和创业浪潮不断涌动,有鹿机器人创始人、CEO陈俊波,是那个让开源大模型更接近商业化落地的人。“国内有几万家传统专业设备生产制造商,但是他们没有能力去研发人工智能系统。我们的使命就是,给每个专业设备提供一个通用的人工智能大脑。”
举例来看,在清洁行业,物业经理说“在一号楼门前有一个可乐瓶,你过来扫一扫”。有鹿机器人在路面清洁机器人中集成Qwen-7B,使机器人能以自然语言与用户进行实时交互,理解用户提出的需求,将用户的高层指令进行分析和拆解,做高层的逻辑分析和任务规划,完成清洁任务。

随着越来越多的开发者和企业加入到开源模型阵营,开源模型的生态逐渐形成气候,“高质量开源基础大模型-大模型优化-AI应用创新”的商业化落地发展路径也变得清晰起来。
为什么选择开源大模型?
2023年,是AI大模型快速发展的一年。伴随ChatGPT的横空出世,国产大模型的数量也快速增长,数据显示,截至今年10月,国内已发布238个大模型。
目前,大模型行业主要有两条技术路线,一个是以OpenAI的GPT4.0为代表的闭源路线,马斯克曾评价其一点也不Open,一条是以Meta的Llama2、阿里QWen等为代表的开源路线,后者在创投领域更受追捧。
百模大战当前胜负未分,开源、开放、开发者,或是当下能最大限度激发创业热情的连接方式。
“我们没有资源从头训练一个基座模型,选模型的第一个考量就是,它背后的机构能不能给模型很好的背书,能不能持续投入基座模型及其生态建设,为跟风、吃红利而生的大模型不可持续。”颜鑫分享称,他希望选择主流的、稳定的模型架构,它能最大限度发挥生态的力量,匹配上下游的环境。
开源大模型可以帮助用户简化模型训练和部署的过程,使得用户不必从头训练模型,只需下载预训练好的模型并进行微调,就可快速构建高质量的模型或进行相应的应用开发。
而在陈俊波看来,他需要的不是一个一成不变的、智能性水平的大语言模型,而是随着数据的积累,能变得越来越聪明的大语言模型。闭源大模型显然做不到这一点。所以在他们的业态里面,终局一定是开源模型。

同时,未来速度联合创始人兼CEO秦续业提出,开源大模型在B端大有可为,企业级用户更在意的是能不能解决问题,而非要求模型能力面面面俱到。开源大模型更可控、定制化强、更具性价比。具体而言,经过简单微调,开源大模型能满足很多B端场景需求,同时开源大模型推理成本大约只有闭源收费大模型的1/50。
通义千问助力生态繁荣
大模型开源之风渐起。优质大模型的开源有助于促进中国大模型的技术进步与应用落地,推动大模型技术普惠。然而,目前国内市面上有100多个大模型,只有少数是高质量开源的。
此前,中国大模型市场暂未出现足以对捍Llama 2-70B的优质开源模型。12月1日,阿里云开源通义千问720亿参数模型Qwen-72B,填补了国内空白,大中型企业可基于Qwen-72B开发商业应用,高校、科研院所可基于Qwen-72B开展AI for science等科研工作。
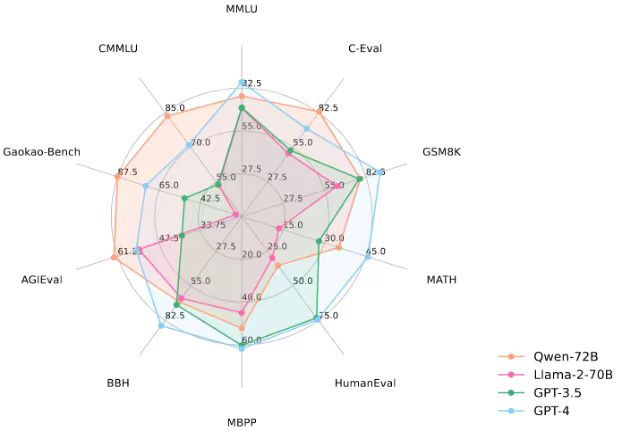
此外,阿里云同步开源了通义千问18亿参数模型Qwen-1.8B和通义千问音频大模型Qwen-Audio,至此,通义千问开源光谱覆盖18亿、70亿、140亿、720亿参数的4款大语言模型,以及视觉理解、音频理解两款多模态大模型,实现“全尺寸、全模态”开源。
作为国内最早开源自研大模型的科技公司之一,阿里云对打造大模型开源生态不遗余力,如今,补齐开源大模型的最后一片拼图,是通义千问的关键一役。
阿里云CTO周靖人表示,开源生态对促进中国大模型的技术进步与应用落地至关重要,通义千问将持续投入开源,希望成为“AI时代最开放的大模型”,与伙伴们共同促进大模型生态建设。
本网站上的内容(包括但不限于文字、图片及音视频),除转载外,均为时代在线版权所有,未经书面协议授权,禁止转载、链接、转贴或以其他 方式使用。违反上述声明者,本网将追究其相关法律责任。如其他媒体、网站或个人转载使用,请联系本网站丁先生:news@time-weekly.com






